
ChatGPTに大量の文章を学習させる方法
最近 ChatGPT を使ったアプリケーションがたくさん出てきていますね。ChatGPT に社内 wiki やブログを読み込ませて、それをもとに質問に回答させるようなアプリケーションにトライしているのもちょくちょく見かけます。 同じようなアプリケーションを作ってみたいが、実際どんな原理で実現しているのでしょう。少し調べてみました。
ChatGPT に学習させる方法について
ChatGPT では内部で GPT という言語モデルを使っています。
こうした言語モデルに新しく情報を学習させる方法は大きく分けて3つあります。
- 学習段階から自社データを学習データに入れておく方法
- 学習済みのモデルに自社データを入れてファインチューニングする方法
- プロンプトで学習させる方法
1 の場合、GPT のモデルは OpenAI が作成しているものなので、学習段階から明示的に自分が追加で学習させたい内容を盛り込むことはできません。このように事前に学習させたモデルのことを事前学習済みモデルと呼び、ChatGPT ではこのモデルをもとに、様々な自然言語タスクに応用することができています。 2 のように事前学習済みモデルに追加で学習させることをファインチューニングと呼び、自分たち独自のデータを追加で学習させる方法として最も一般的だと思います。 しかし、ChatGPT では現在ファインチューニングをサポートしていません。
したがって 3 のプロンプトで学習させる方法が ChatGPT においては最も一般的な学習方法と言えるでしょう。
プロンプトとは
プロンプトとは、ChatGPT に与える入力情報のことです。プロンプトには、回答に必要な情報を適切に与える必要があります。以下のような情報が含まれることが多いでしょう。
- 質問文や要求事項の文言
- 質問文や要求事項の文脈となる情報(例:商品やサービスの名前、地名、期間、数量など)
- 回答に必要な情報の整形方法(例:データのフォーマット変換、要約、加工など)
- 回答に必要な情報の出力方法(例:テキスト、音声、画像、動画など)
プロンプトエンジニアリングという言葉もありますが、プロンプトに与える情報の考え方は、ChatGPT の性能に大きく影響するため、非常に重要な要素です。社内情報やブログなどの情報を、質問や要求事項の文脈となる情報としてプロンプトに渡すことで、ChatGPT はそれをもとに回答を生成してくれます。 学習させるという単語を使っているので、ChatGPT はプロンプトに与える情報を学習しているように見えますが、実際にはプロンプトに与える情報をもとに、回答を生成させているだけです。
# プロンプトの例
# 質問文
〇〇プロジェクトの中で決めた〇〇という仕様ですが、なぜこのような仕様になってましたっけ?
# 質問文の文脈となる情報
{ここに社内の情報を記述する}
# 出力
上記のような質問を ChatGPT に投げれば、ChatGPT は社内の情報をもとに回答を生成してくれるはずです。
プロンプトの制約
では学習させたい全ての情報をプロンプト内に記述することができるのでしょうか。実はそうではありません。
ここでトークンについての理解が必要になります。トークンとは自然言語のテキストデータを分割した最小単位のことを指しており、プロンプトはトークンを並べた文字列として表現されます。プロンプトに渡せる質問文やそれに関連する情報は全てトークンとして処理されるわけです。
ChatGPT では一度に渡せるトークン数に上限があり、GPT-3.5 では最大 4096 トークン、GPT-4.0 では最大 8192 トークンとなっています。上限を超えるとエラーが発生します。 日本語は大体1文字で1トークンと計算されるため、だいたい 4000 文字程度しか渡すことができません。
この最大トークン制約があるため、単純にプロンプトに全ての情報を記述することはできません。プロンプトに与える情報を適切に整理し、必要最低限の情報をプロンプトに渡すことが重要です。
この上限は、ChatGPT が生成する回答の長さに制限があるためです。この上限を超えると、ChatGPT は回答を生成することができないため、エラーが発生します。
少し余談ですが、ChatGPT では会話の履歴を保持しているように思えますが実はそうではありません。 毎回の質問ごとに過去の会話履歴もプロンプトに渡すことで、会話の文脈を加味して返答しているだけなのです。 会話が長くなればいずれ最大トークン数を越えてしまうため、過去の会話を削ぎ落としていくようです。 したがって会話の履歴が長くなればなるほど、ChatGPT は始めの方の会話の文脈を考慮できなくなっていきます。
このように一度に渡せる情報量に上限がある ChatGPT に対して、どのようにすれば大規模な情報を学習させることができるのでしょうか。 いくつか手法はあるようですが、今回はプロンプトに渡す前段にベクトルベースの文章検索を挟む方法を紹介します。
文章ベクトルを使った検索方法
OpenAI にはEmbeddings API が存在します。 Embeddings では事前学習されたモデルを利用して、単語や文章のベクトル表現を取得することができます。
以下は Amazon のレビュー文章のベクトル表現を2次元にプロットしたものです。プロットの点の色は、レビューの評価を表しています。同じ色の点が近くに集まっていることがわかりますが、これは悪い評価のレビューや良い評価のレビュー文章は近い場所にプロットされていることを示しています。
このことから文章の類似性をベクトル空間上の距離で表現することができることがわかります。

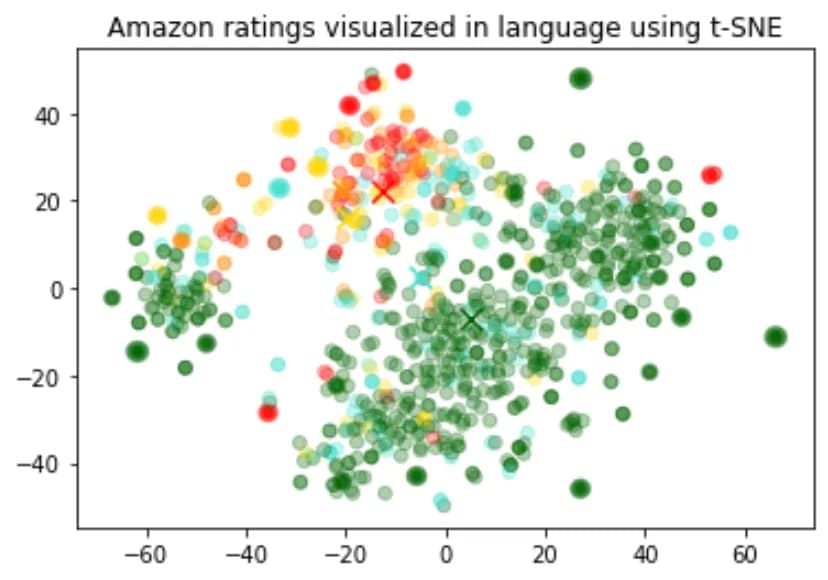
引用元:https://platform.openai.com/docs/guides/embeddings/use-cases
具体的な手順
Embeddings を使って文章を検索する場合、以下のような手順で行うことができます。
- 検索対象となる社内情報やブログ記事など、全ての文章をベクトル化する
- ベクトル化した文章を永続情報として保存する
- 質問文をベクトル化する
- ベクトル化した質問文と保存したベクトル化した文章を比較し、質問文と類似度の高い文章を検索し、取得する
引用元:https://cloud.google.com/vertex-ai/docs/matching-engine/overview
質問文と文章の類似度は最近傍法によって計算されるのが一般的なようです。
こうして取得した文章をプロンプトに渡すことで、ChatGPT は検索された文章の文脈を考慮した回答を生成することができます。
# プロンプトの例
# 質問文
〇〇プロジェクトの中で決めた〇〇という仕様ですが、なぜこのような仕様になってましたっけ?
# 質問文の文脈となる情報
{検索して取得された、質問と類似性の高い文章をここに埋め込む}
# 出力
このプロンプトに渡す前に検索を行うという行為は、短期記憶と長期記憶という概念で考えるとイメージしやすいと思います。 長期記憶である文章ベクトル空間から関連する情報を抽出し、短期記憶であるプロンプトに渡すことで、ChatGPT はより正確な回答を生成することができます。
まとめ
今回は ChatGPT に情報を学習させることについて説明しました。 現在では一度に渡せる情報量に限りがあるため、利用者自身が渡す情報を工夫する必要があります。 こうした制限は徐々に緩和されていくでしょうし、あるいは今回紹介したような文章ベクトルを使う方法も今後はツール内に内包され、透過的に利用できるようになると思います。
しかし内部でどのように情報が処理されているかを理解しておけば、今後の活用イメージを広げることことができると思います。